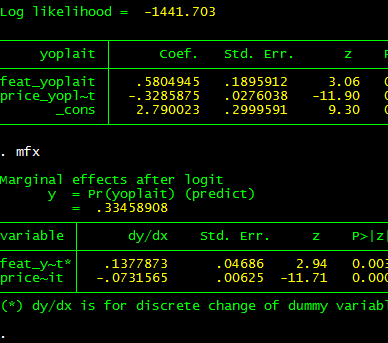
But I don't just stop on any card. I stop on your current special card. Which I'm not supposed to know.
- I put a deck of cards down face up on the table. Meanwhile you think of a secret number between 1 and 10 -- for exposition let's say you pick 4.
- One by one, I discard cards from the top of the deck. When we get to the 4th card -- and let's call it your special card -- you look at the number. For exposition, let's say your special card happens to be a 7. Then 7 secretly becomes your new number. Note that I don't know your special card.
- I keep flipping cards, and 7 cards later, you have a new special card and number yet again. Note that I still don't know your special card.
- This process continues -- me flipping cards at a constant rate, you secretly updating your special card and counting up to the next one -- until I decide to stop.
The following script file is a crude first approximation to simulating this card trick for the first 150 cards. This crude strategy is simple: (1) Simulate a sequence of 150 cards, (2) Pick a starting value -- might as well do all of them at once, and (3) Implement Xan's trick on all of them (that's what the for loop does).
Here's the result of running this script three times and plotting 10 secretnum sequences: one for each starting value. Each run starts with 10 distinct secret numbers (with a default chance of 0.1 of the trick "working"), and in my three runs, every starting value of the secret number eventually converges on the same sequence of secret numbers. More on the intuition for this here.

There are a couple of things wrong with this simulation that may have stacked the deck in favor of it working. I fixed these before writing this post, but I think it is useful to see the quick and dirty solution before adding frills and realism (which is what I do now).
- I merely simulated my 150 cards using a uniform distribution on 1 to 13 (then forcing the face cards 11, 12 and 13 to be 10s). This is equivalent to sampling with replacement, which may have different properties than sampling without replacement.
- There are only 52 cards in a deck. How would this work with only one shuffle, but passing through the deck (almost) three times until 150 cards? This is a different problem. Maybe you wouldn't expect much improvement after one pass through the deck (because you've seen that sequence of cards before).
Once you define this function, we can save the probability of the trick working for 1000 different shuffles of the cards. This script does it for one deck and one pass through the deck.
Then, we can take the average probability, which feels like the probability the trick works (unconditional on the particular shuffle or guess of a secret number). In the simulations I have run, this number turns out to be around 0.74 for one deck and one pass through the deck and about 0.86 using one deck and passing through twice. There's not much improvement after the second pass through of the deck.
In case you're interested, here are the results for up to 3 decks and up to 5 passes through the set of cards. It is always better to have more decks, but two passes through two decks is about enough to virtually guarantee that the trick works.

Update: In case you are wondering, I also coded it up with a 0.01 probability of forgetting to update on any given flip of the card. Here's the table of results in this case.

It's no surprise: For forgetful people, the trick is less successful and there isn't much point in reaching for a second deck.